ReadingTracker
![]()
![]()
Content
What is that?
The project is expected to help you to read books:
- Keep a list of books you want to read;
- Keep a list of reading and completed materials;
- Calculate statistics;
- Track the reading log;
- Take notes to help you remember some important points from the material.
Installation
- Clone the repo:
git clone https://github.com/kunansy/ReadingTracker. - Create the Google Drive service account: https://labnol.org/google-api-service-account-220404, first 4 steps.
- Create env file and fill it:
cp env.template .env. - Run docker container:
docker compose up -d --build --force-recreate - Migrate the database:
docker exec -i -t tracker-app python3 /app/tracker/main.py
Structure
Queue
Here there are the books, articles, courses etc. to read with some analytics,
the expected reading time according to the mean pages read.

Reading
Here there are the materials you are currently reading.

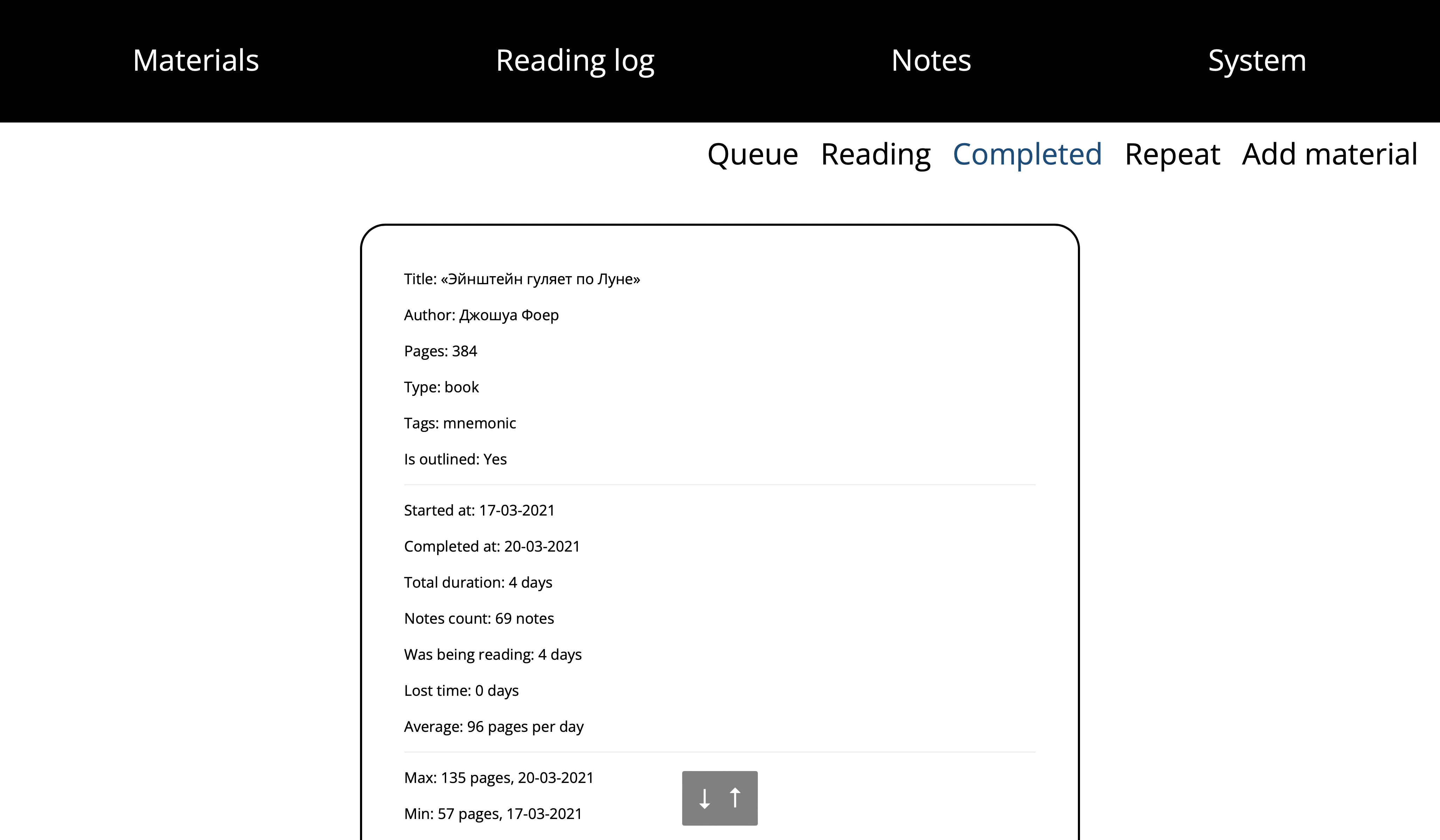
Completed
Here there are the materials that have been read.
Repeat
Here there are the materials that have been read and need to be read again, repeated after a month or more.
The priority is equal to the number of months since the material was last read or repeated.

Reading log
Here there is the reading log of the materials. The day is red if
there are less than average pages, green if there are more.

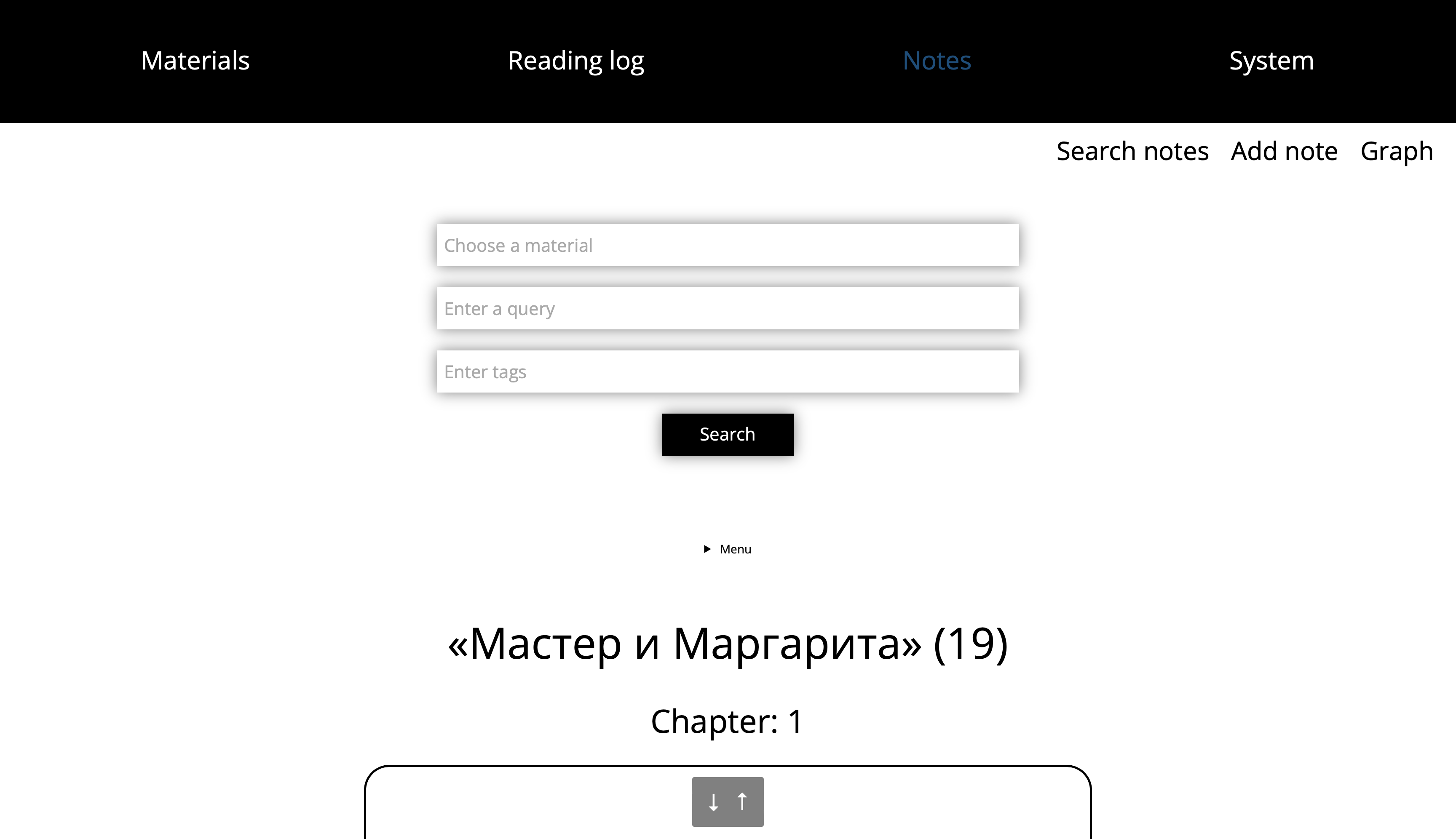
Notes
Here there are notes, the most important info from the materials.
The user can search a note with Manticoresearch by any text query,
filter notes by materials or tags.
You should:
- Create small notes with one idea in each note.
- Add tags that helps to link some ideas into topic groups:
#health,#history,#linguisticsetc. - Add links to help connect notes together using Zettelkasten method.
- Each note should be linked to a note that is directed linked to it, as follows:
[[c2ed0ac7-fe4f-4a23-a00c-8f61d16398ea]]
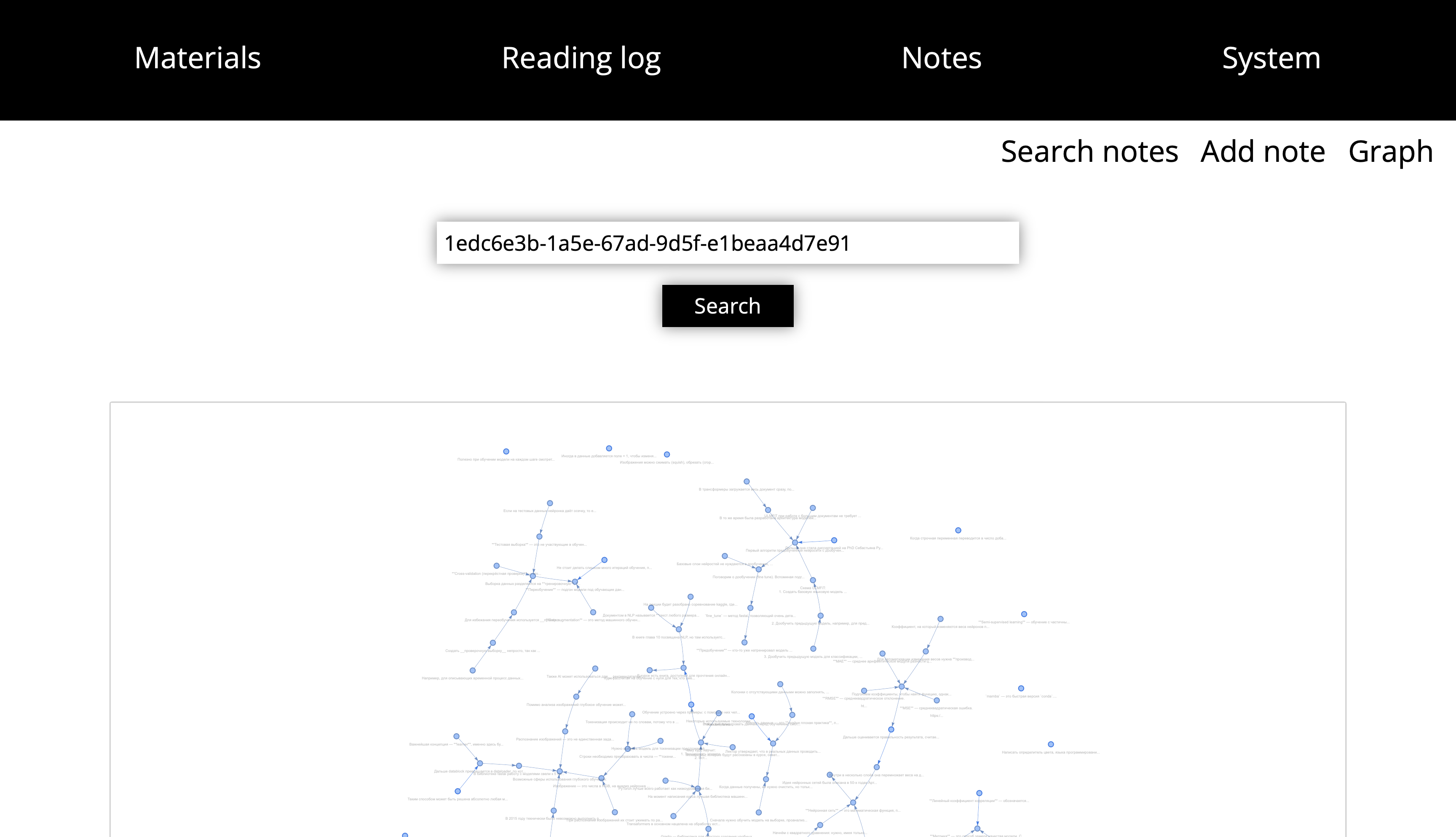
Notes graph
Also, here there is a graph with all notes.
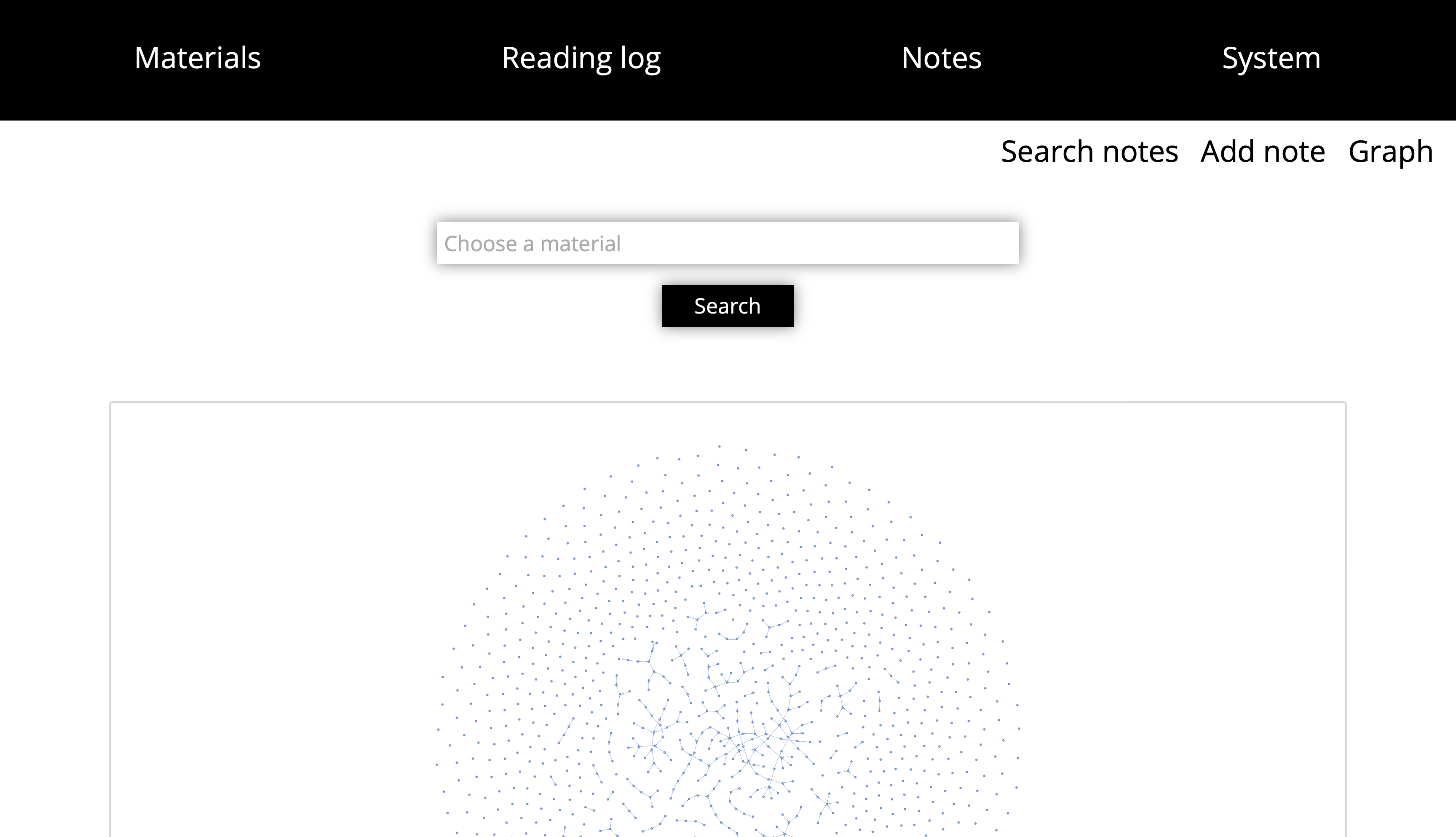
Or graph for selected material.
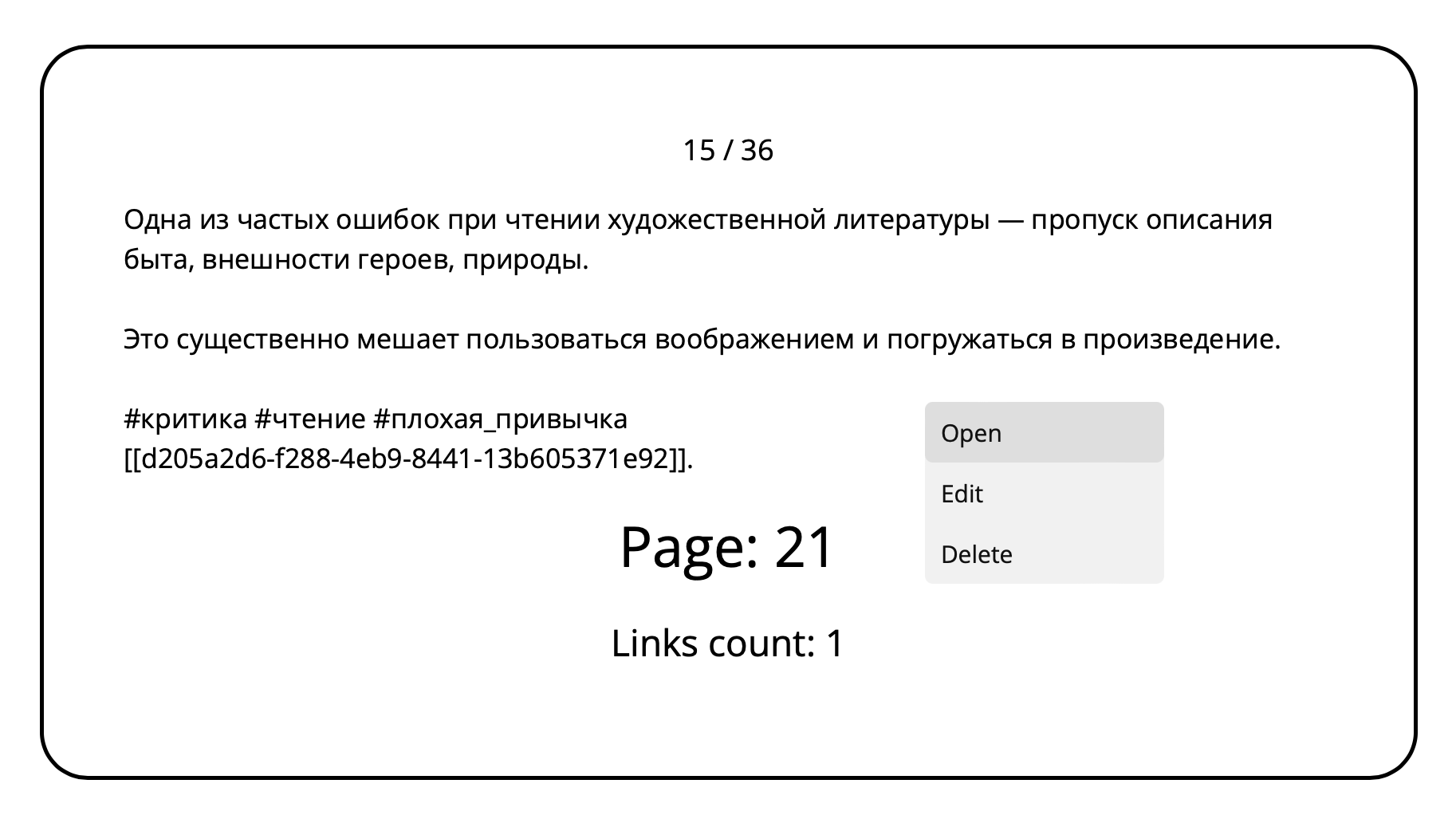
Note context menu
The user can open a note with context menu, edit it or delete.
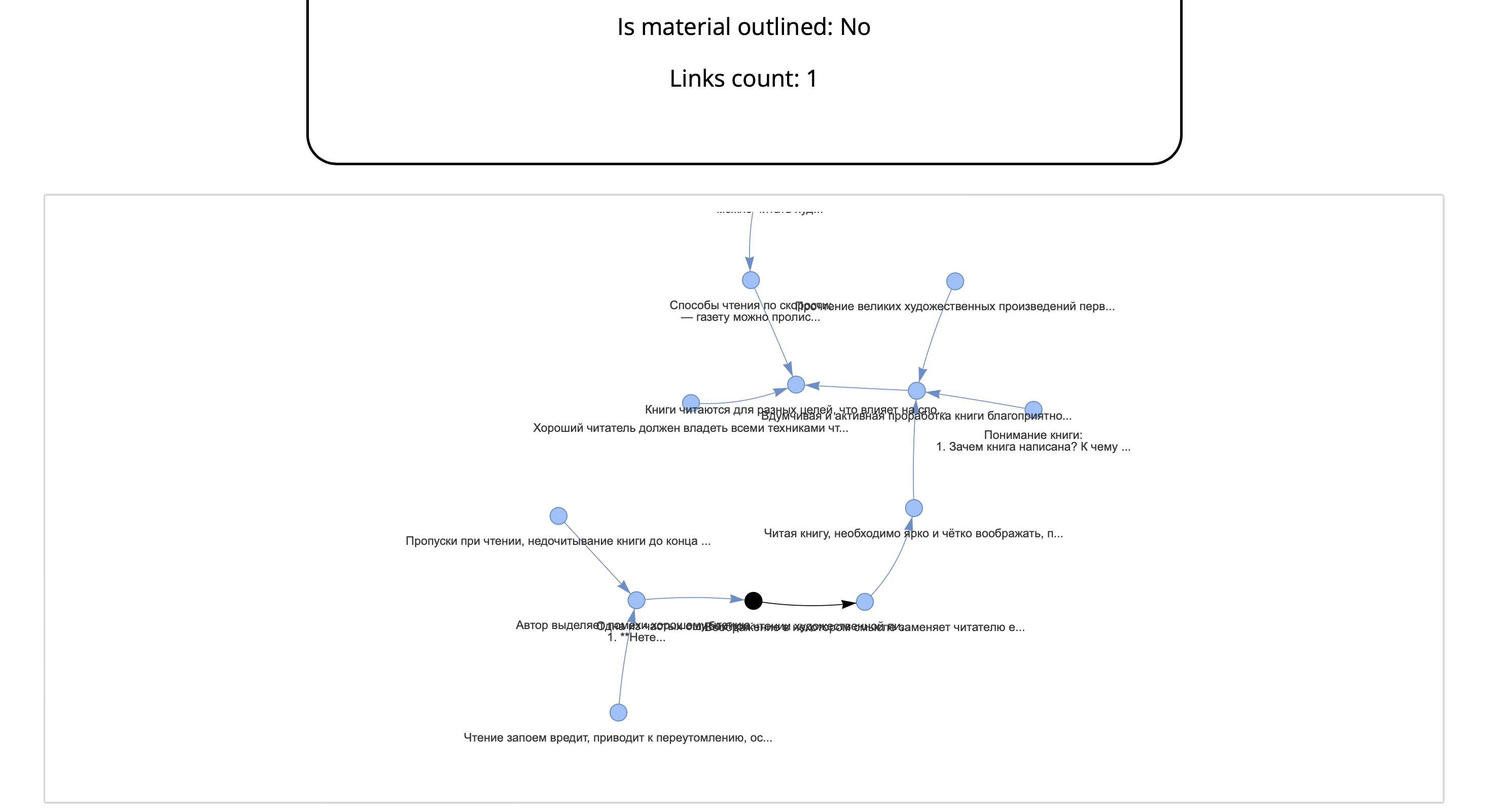
Show the note
Using these arrows user can iter over all note links.

Here is a graph with the current note links.
Edit the note
When edit the note the user can:
- Use speech recognition and enter text using a voice (buttons
Start,Stop); - Choose some compatible tags (tags are sorted so that the ones used in notes for this material come first);
- Choose the link to another note: there are only notes with the same tags ordered by tags intersection.
Tags and links lists might be scrolled left/right.

System
Here there are reading graphic, backuping and restoring from the Google Drive.
All graphic shows statistics for chosen time span (a week by default).
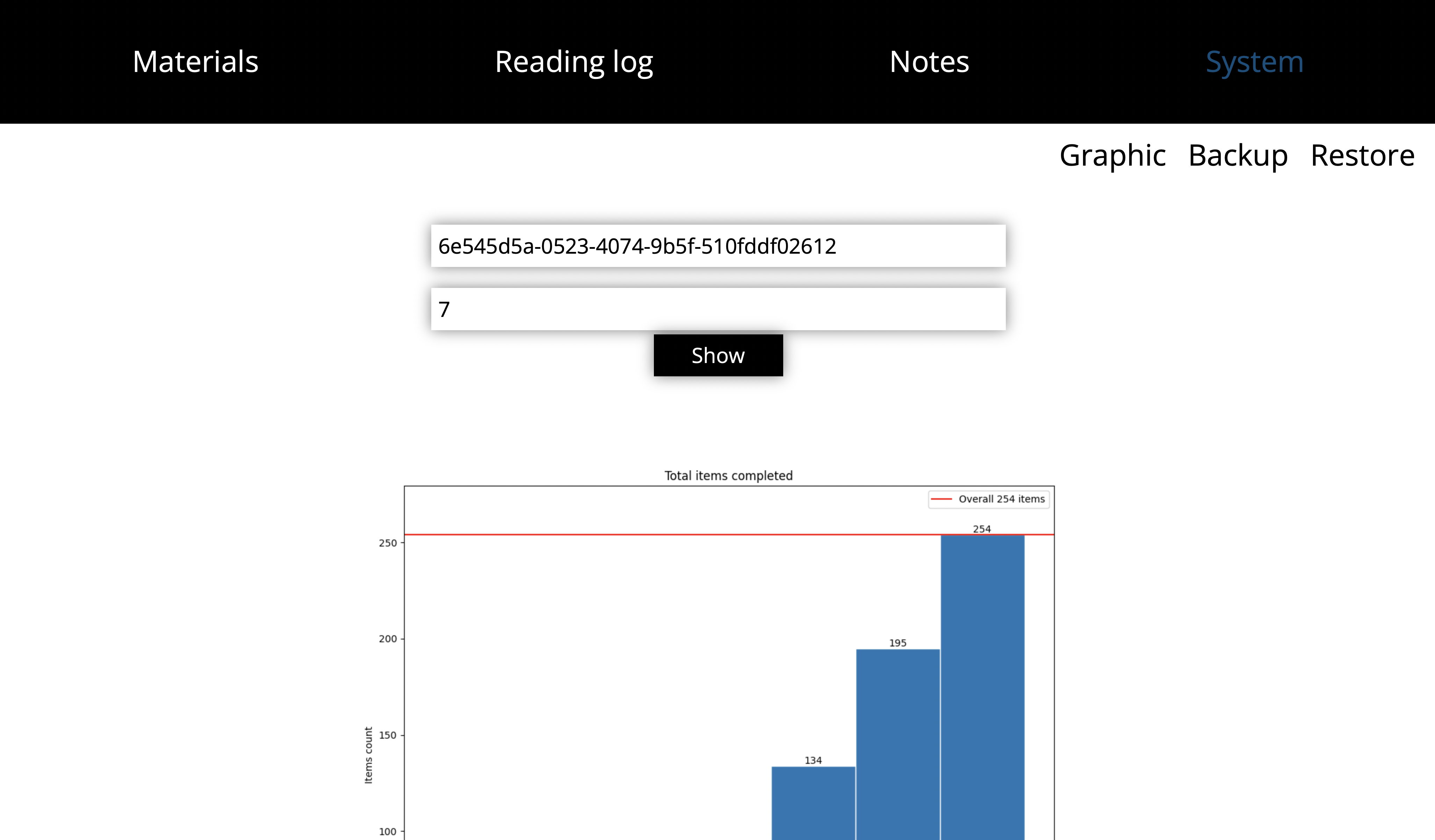
Material reading graphic
How the material was being reading:
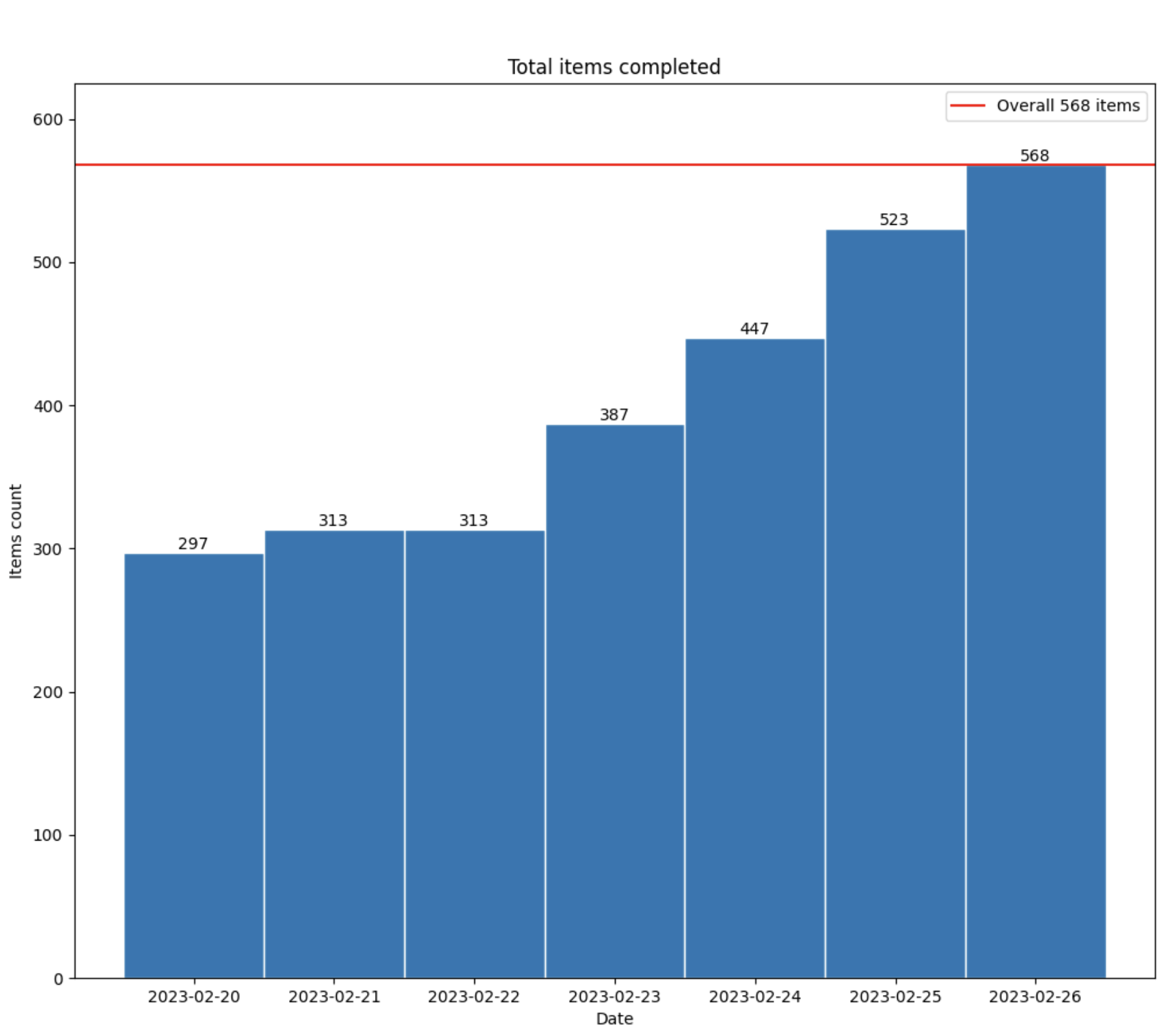
Tracker statistics
![]()
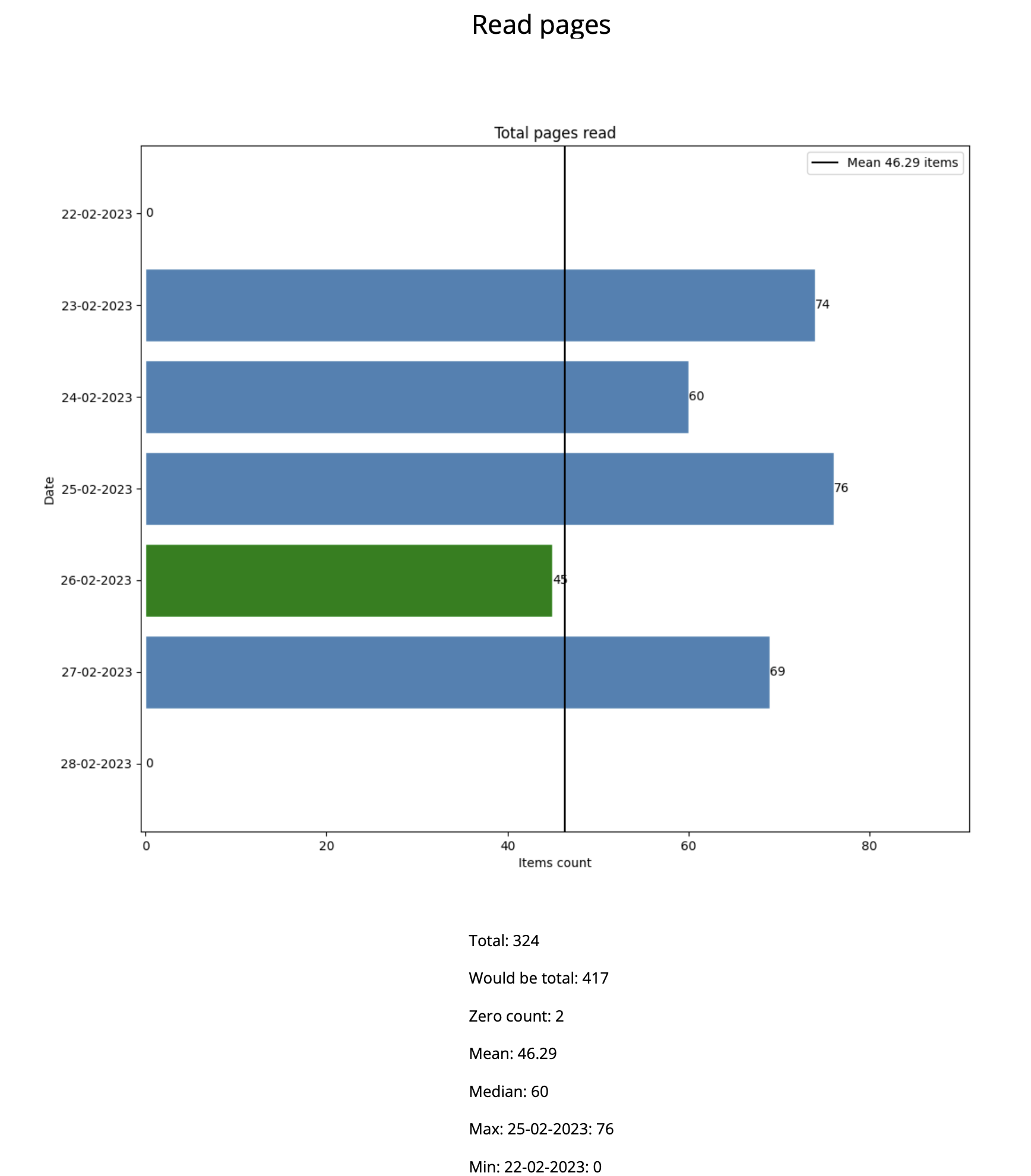
Read pages statistics
Statistics of read pages for the time span.
Would be total— how many pages would be read if there were no empty days;- A day when a material was completed is marked in green.
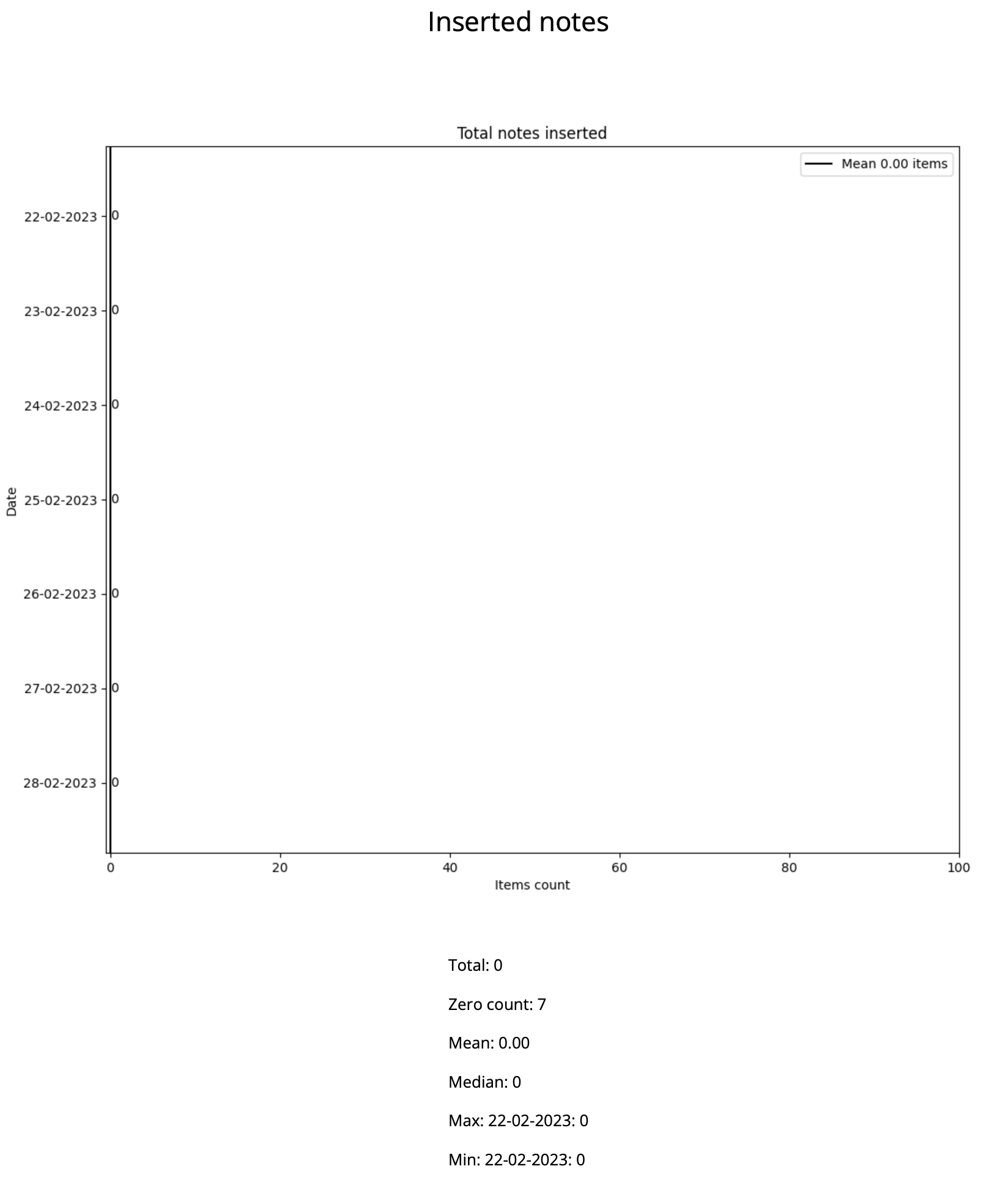
Inserted notes statistics
Statistics of inserted notes for the time span.