RNC
API for Russian National Corpus
![]()
![]()



Installation
pip install rnc
Structure
Corpus object contains list of obtained examples.
There are two types of examples:

- If
outisnormal, API uses normal example, which name is equal to the Corpus class name:
ru = rnc.MainCorpus(...)
ru.request_examples()
print(type(ru[0]))
>>> MainExample
- if
outiskwic, API usesKwicExample.
Examples’ objects fields
Usage
import rnc
ru = rnc.MainCorpus(
query='корпус',
p_count=5,
file='filename.csv',
marker=str.upper,
**kwargs
)
ru.request_examples()
query– one str or dict with tags. Words to find, you should give the vocabulary form of them.p_count– count of PAGES.file– path to local csv file, optional. Example:file='data\\filename.csv'.marker– function, with which found wordforms will be marked, optional.kwargs– additional params.
Corpora you can use.
Full query form
query = {
'word1': {
'gramm': 'acc', # grammar tags for lexgramm search
'flags': 'bdot' # additional tags for lexgramm search
},
# you can get as a value one string or dict of params
# params are: any name of dict key, name of tag (you can see them below)
'word2': {
'gramm': {
# the NAMES of these keys might be any
'pos (any name)': 'S' or ['S', 'A'], # one value or list of values,
'case (any name)': 'acc' or ['acc', 'nom'],
},
'flags': {}, # all the same to here
# distance between first and second words
'min': 1,
'max': 3
},
}
corp = rnc.MainCorpus(
query, 5, file='filename.csv', marker=str.upper, **kwargs)
corp.reques_examples()
String as a query
Also you can pass as a query a string with the vocabulary forms of the
words, divided by space: query = 'get down' or query = 'я получить'.
Distance between them will be default.
Additional request params
These params are optional, you can ignore them. Here are the default values.
corp = rnc.ParallelCorpus(
query=query,
p_count=5,
file='filename.csv',
marker=str.upper,
dpp=5, # documents per page
spd=10, # sentences per document (<= than spd)
text='lexgramm' or 'lexform', # way to search
out='normal' or 'kwic', # output format
kwsz=5, # if out=kwic, count of words in context
sort='i_grtagging', # way to sort the results, see HOWTO section below
mycorp='', # see HOWTO section below
lang=rnc.Languages.en,
accent=0, # with accentology (1) or without (0), if it is available
)
API can work with a local file too
ru = rnc.SpokenCorpus(file='local_database.csv') # it must exist
print(ru)
If the file exists, API works with it. If the data list is not empty you
cannot request new examples.
If you work with a file, it is not demanded to pass any argument to Corpus
except for the file name (file=...).
Working with corpora
corp = rnc.corpus_name(...)
corp.request_examples()– request examples. There is an exception if:- Data still exist.
- No results found.
- A requested page does not exist (if there are 10 pages in the RNC, but you have requested > 10).
- There is a mistake in the request.
- You have no access to the Internet.
- There is a problem while getting access to RNC.
- another problems…
corp.data– list of examples (only getter)corp.query– query (only getter).corp.forms_in_query– requested wordforms (only getter).corp.p_count– requested count of pages (only getter).corp.file– path to the local csv file (only getter).corp.marker– marker (only getter).corp.params– dict, HTTP tags (only getter).corp.found_wordforms– dict with found wordforms and their frequency (only getter).corp.ex_type– type of example (only getter).corp.amount_of_docs– amount of docs where the query was found.corp.amount_of_contexts– amount of contexts where the query was found.corp.graphic_link– link to the graphic of the distribution of query occurrences by years.corp.dump()– write two files: csv file with all data and json file with config.corp.copy()– create a copy.corp.shuffle()– shuffle data list.corp.sort_data(key=, reverse=)– sort the list of examples. Here HTTP keys do not work, key is applied to Example objects.corp.pop(index)– remove and return the example at the index.corp.clear()– empty the data list.corp.filter(key)– filter the data list, remove some examples using the key. Key is applied to theExampleobjects.corp.url– URL of the first RNC page (only getter).corp.findall(pattern, args)– get all examples where the pattern found and the match.corp.finditer(pattern, args)– get all examples where the pattern found and the match.async corp.request_examples_async()– make request in the running event loop.
Magic methods:
corp.dppor another request param (only getter).corp()– all the same torequest_examples().-
str(corp) or print(corp)– str with info about Corpus, enumerated examples. By default, Corpus shows first 50 examples, but you can change it or turn the restriction off.Info about Corpus:
Russian National Corpus (https://ruscorpora.ru) Class: CorpusName, len = amount of examples Pages: n of 'words' requested len(corp)– count of examples.bool(corp)– whether data exist.corp[index or slice]– get element at the index or create a new object with sliced data:from_2_to_10 = corp[2:10:2]-
del corp[10]ordel corp[:10]– remove some examples from the data list. - Also you can use cycle
for. For example we want to see only left context (out=kwic) and source: ```python corp = rnc.ParallelCorpus( ‘corpus’, 5, out=’kwic’, kwsz=7, lang=rnc.Languages.en ) corp.request_examples()
for r in corp: print(r.left) print(r.src)
Set default values to all objects you will create:
* `corpus_name.set_dpp(value)` – change default `document per page` value.
* `corpus_name.set_spd(value)` – change default `sentences per document` value.
* `corpus_name.set_text(value)` – change default search way.
* `corpus_name.set_sort(value)` – change default sort key.
* `corpus_name.set_min(value)` – change default min distance between words.
* `corpus_name.set_max(value)` – change default max distance between words.
* `corpus_name.set_restrict_show(value)` – change default amount of shown examples in print.
If it is equal to `False`, the Corpus shows all examples.
### Corpora features
#### ParallelCorpus
* The query might be both in the original language and in the language of
translation.
#### MultilingualParaCorpus
* Working with files is removed.
* Param `mycorp` is not demanded by default, but it might be passed, see
**HOWTO** section below.
#### MultimodalCorpus
* `corp.download_all()` – download all media files. **It is recommended** to use
this method instead of `expl.download_file()`.
* `async corp.download_all_async()` – download all media files using the running event loop.
## Logger
* See all log messages
```python
rnc.set_stream_handler_level('debug')
- See less than all messages
rnc.set_stream_handler_level('info') - Turn the logger off
rnc.set_logger_level('critical') - Turn off all messages in the stream, but dump logs to file
rnc.set_stream_handler_level('critical') - Turn off dumping logs to file
rnc.set_file_handler_level('critical')
ATTENTION
- Do not forget to call this function
corp.request_examples() - If you have requested more than 10 pages, RNC returns 429 error
(Too many requests).
For example requesting 100 pages you should wait about 3 minutes:

- Do not call the marker you pass
RIGHT:
ru = rnc.MainCorpus(..., marker=str.upper)
WRONG:
ru = rnc.MainCorpus(..., marker=str.upper())
- Pass an empty string as a param if you do not want to set them
query = { 'word1': '', 'word2': {'min': 2, 'max': 5} } - If
accent=1, marker does not work. - Do not run
corp.request_examples()in the running event loop, instead useawait corp.request_examples_async()
HOWTO
You can ask any question you want here.
How to set sort?
There are some sort keys:
i_grtagging– by default.random– randomly.i_grauthor– by author.i_grcreated_inv– by creation date.i_grcreated– by creation date in reversed order.i_grbirthday_inv– by author’s birth date.i_grbirthday– by author’s birth date in reversed order.
How to set language in ParallelCorpus?
en = rnc.ParallelCorpus('get', 5, lang=rnc.Languages.en)
Languages the corpus supports:
- Armenian
- Bashkir
- Belarusian
- Bulgarian
- Buryatian
- Chinese
- Czech
- English
- Estonian
- Finnish
- French
- German
- Italian
- Latvian
- Lithuanian
- Polish
- Spanish
- Swedish
- Ukrainian
If you want to search something by several languages, choose and set the
mycorp in the site, pass this param to Corpus.
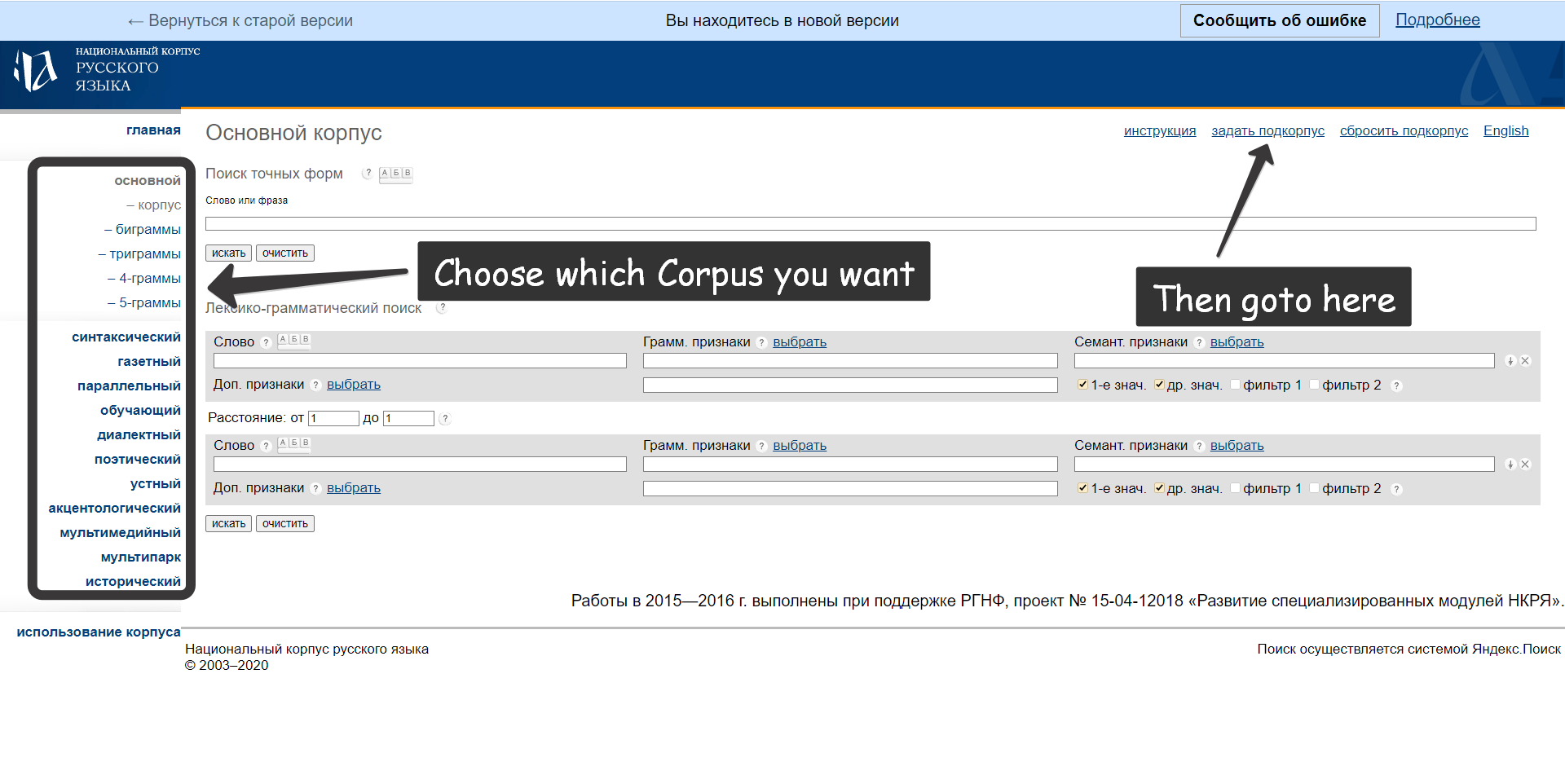
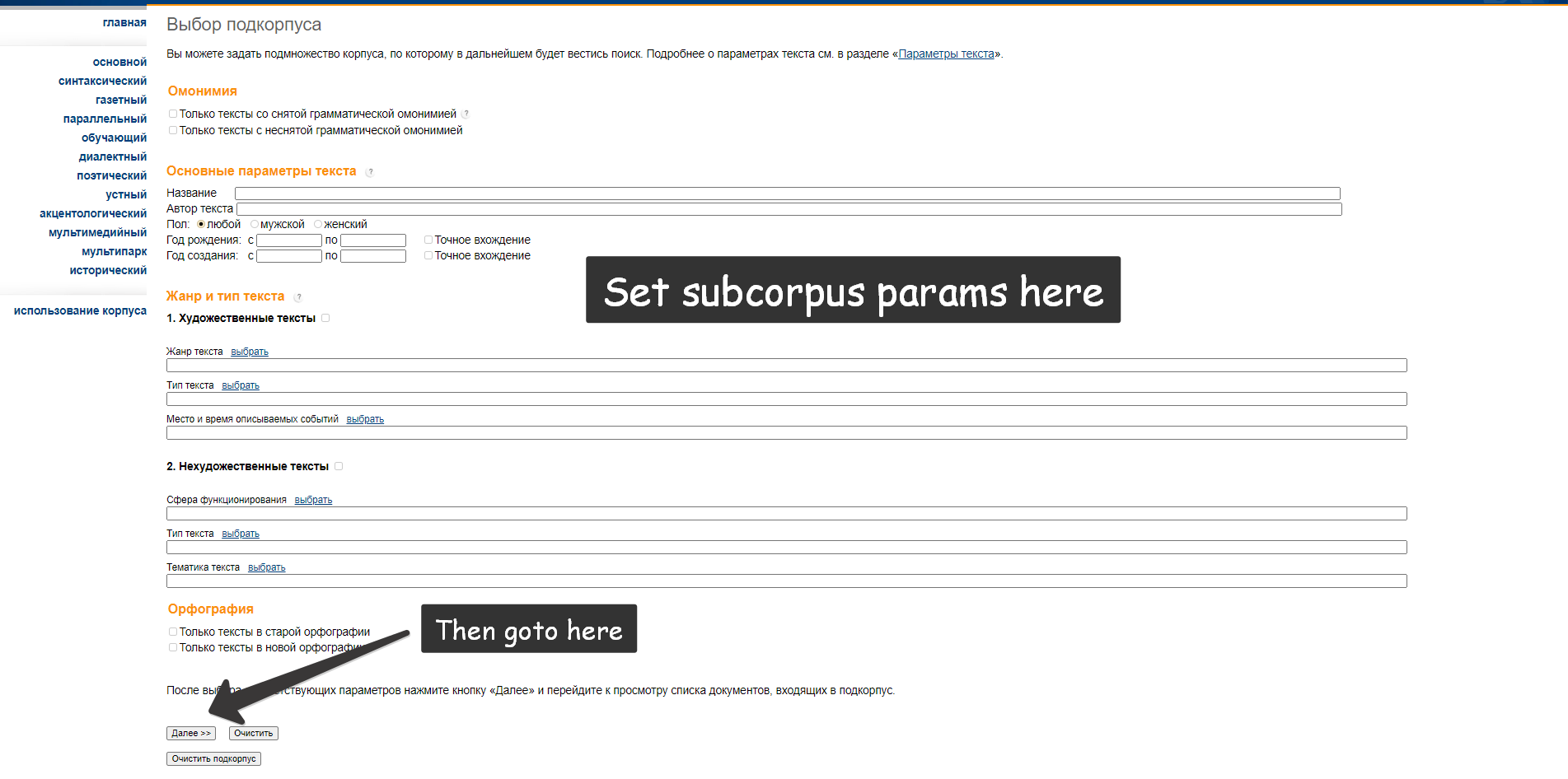
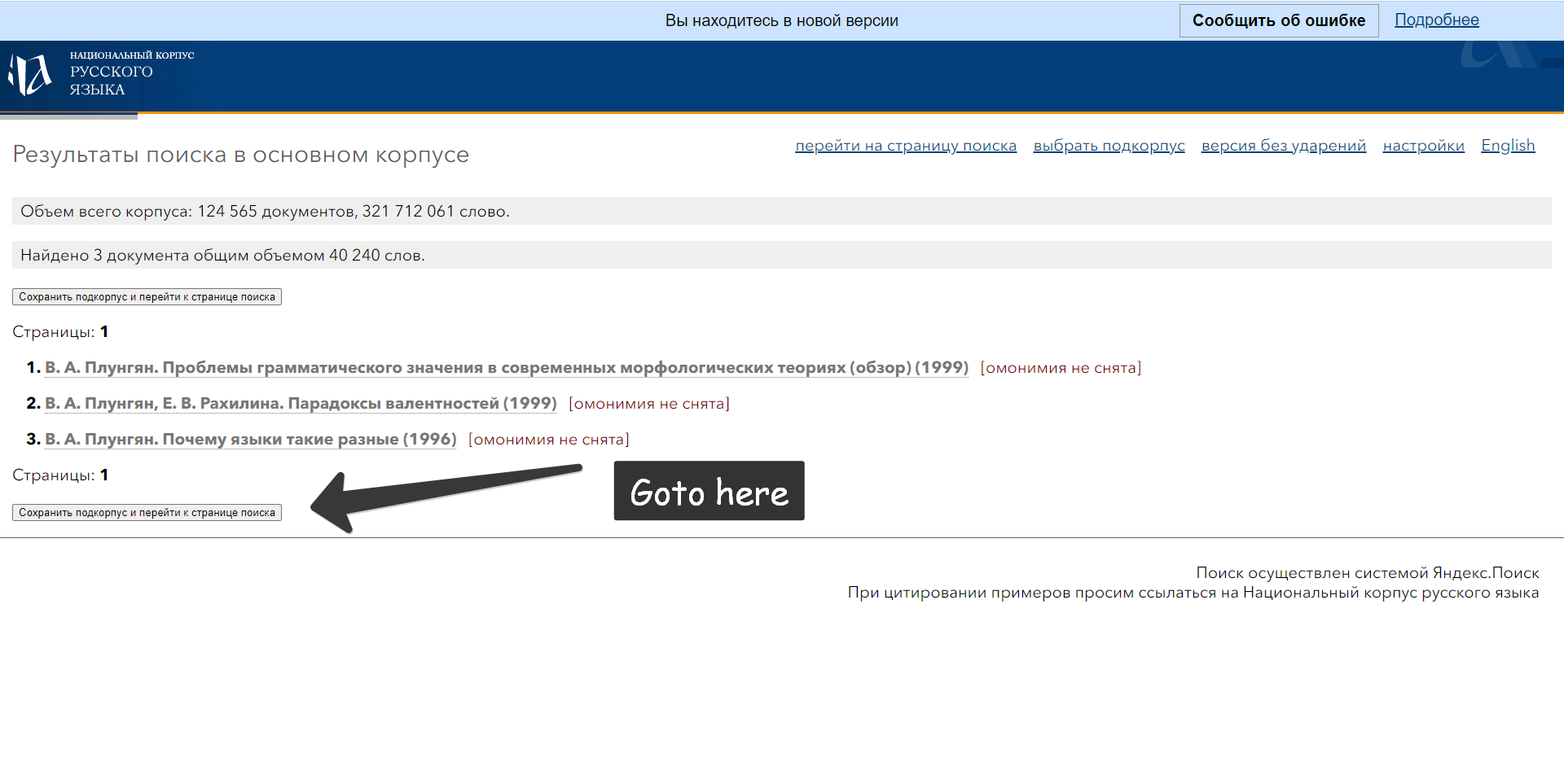
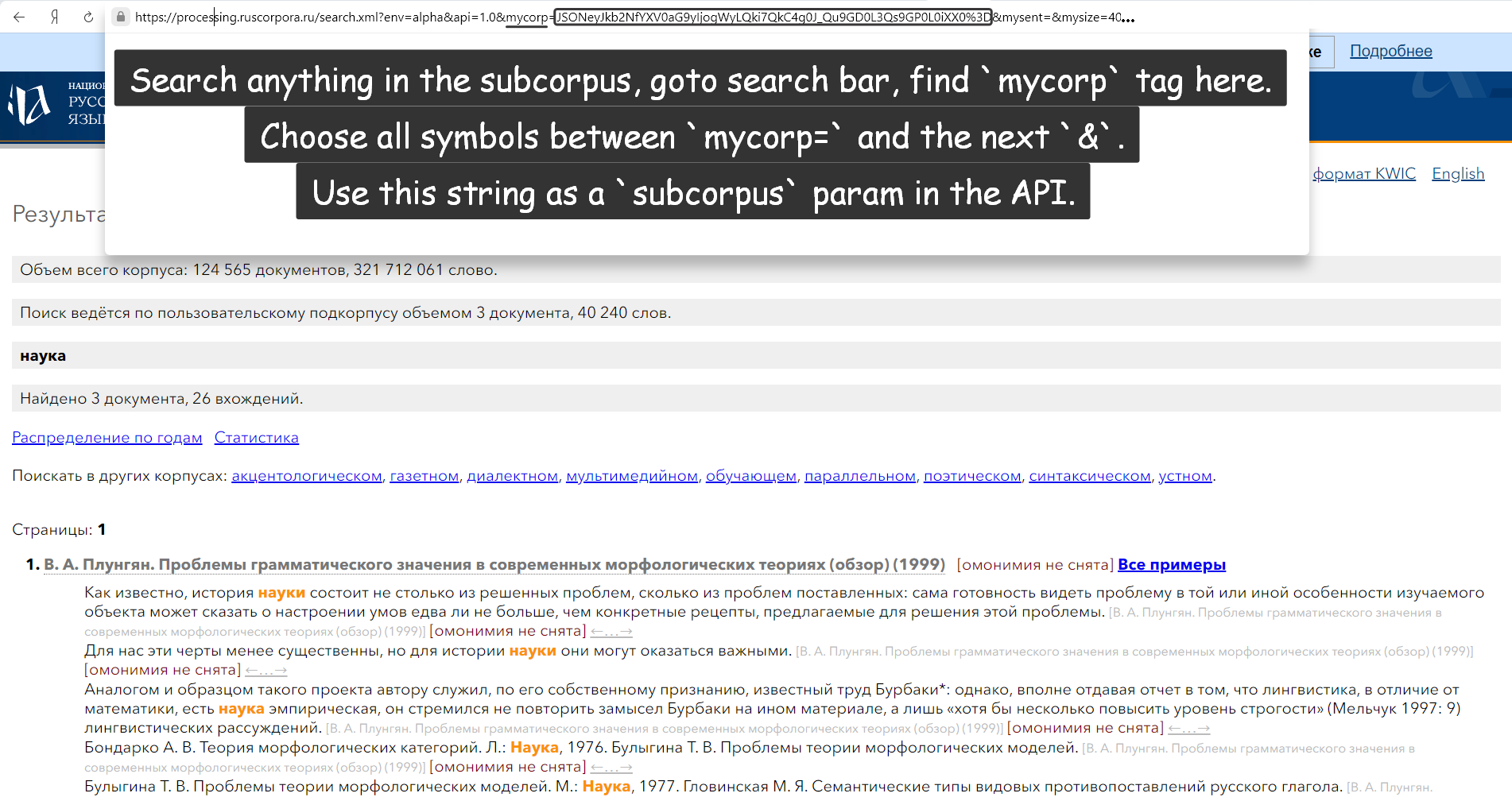
How to set subcorpus?
Means specify the sample where you want to search the query.
There are default keys in rnc.mycorp (working checked in
MainCorpus) – Russian writers and poets:
- Pushkin
- Dostoyevsky
- TolstoyLN
- Chekhov
- Gogol
- Turgenev
Example:
ru = rnc.MainCorpus('нету', 1, mycorp=rnc.mycorp['Pushkin'])
OR
ru = rnc.MainCorpus('нету', 1, mycorp=rnc.mycorp.Pushkin)
OR
Links
- Russian National Corpus
- Docs
- Examples’ objects fields
- Corpora you can use.
- Lexgramm search params
-
Sort keys
Requirements
- Python >= 3.7
Licence
rnc is offered under MIT licence.
Source code
The project is hosted on Github
Please file an issue in the bug tracker if you have found a bug or have some suggestions to improve the library.